06. Automatizace v systému GRASS¶
Cvičení¶
Vstupní data¶
Lidarová data ve formátu LAS/LAZ lze importovat pomocí dvou nástrojů založených na knihovně PDAL:
r.in.pdalvytvoří na základě mračna bodů rastrovou vrtsvuv.in.pdalvytvoří na základě mračna bodů vektorovou bodovou vrstvu
Poznámka
V systému GRASS najdeme také nástroje r.in.lidar a v.in.lidar, které nabízí velmi podobnou funkcionalitu. Tyto nástroje jsou založené na zastaralé a v dnešní době již neudržované knihovně libLAS. Proto je nebudeme používat.
Tvorba rastrového DMR z lidarových dat¶
Nejprve vytvořme nový GRASS projekt v požadovaném souřadnicovém systému (CRS). GRASS neumožňuje detekovat CRS ze vstupního mračna bodů, pro tento účel použijeme konzolový nástroj knihovny PDAL:
Vstupní soubor bohužel neobsahuje definici CRS. Můžeme ji ale odhadnout ze souřadnic prostorového rozsahu. V našem případě se jedná o EPSG:5514:
"bbox":
{
"maxx": -737500,
"maxy": -1038000,
"maxz": 358.82,
"minx": -740000,
"miny": -1040000,
"minz": 203.48
},
Nyní tedy můžeme založit nový projekt na základě EPSG anebo použít již existující projekt z minulé lekce. V tomto případě ale založíme v tomto projektu nový mapset, abychom oddělili od sebe dvě různé analýzy.
Vstupní data do projektu importujme pomocí r.in.pdal s nastaveným prostorovým
rozlišením (resolution) výsledné rastrové vrstvy. Vstupní LAZ
soubory neobsahují informaci o souřadnicovém systému, proto použijme
přepínač -o. Důležitý je přepínač -e, který rozšíří výpočetní
region na základě prostorového rozsahu vstupních lidarových dat.
Úkol
Vhodné prostorové rozlišení spočítejte podle návodu v dokumentaci.

Základní statistiku ve formě reportu vypišme pomocí nástroje
r.report.
Rastrová vrstva obsahuje 7% buněk bez informace:
Tyto chybějící informace doplňme pomocí nástroje r.fill.stats, který
ve výchozím nastavení používá IDW:
Úkol
Vyzkoušejme různé nastavení parametru distance (počet buňek pro
interpolaci). Příklad pro distance=10:

Počet buněk bez informace zjistěte pomocí r.univar nebo r.stats.
Automatizace ve formě skriptu¶
Automatizaci lze provést pomocí jednoduchého skriptu. Příklad pro Bash:
DIR="/mnt/repository/155FGIS/06/dmr5g/"
for file in `ls $DIR/*.laz`; do
tile=`basename ${file%.laz}`
echo $tile
r.in.pdal -oe input=$file output=$tile resolution=5
g.region raster=$tile
r.fill.stats -k input=$tile output=${tile}_filled
r.colors map=${tile}_filled color=elevation
done
Skript spustíme z GUI  .
.
Tip
Skript lze spustit také při startu systému GRASS:
Úkol
Nastavená tabulka barev není mezi jednotlivými dlaždicemi konzistetní.

Tento problém můžeme vyřešit importem všech dlaždic do celistvé mozaiky:
DIR="/mnt/repository/155FGIS/06/dmr5g/"
output="dmr5g"
for f in ${DIR}/*.laz; do
echo $f >> /tmp/seznam.txt;
done
r.in.pdal -e -o output=$output file=/tmp/seznam.txt resolution=5
g.region raster=$output
r.fill.stats -k --overwrite input=$output output=${output}_filled distance=5 mode=wmean power=2.0 cells=8
r.colors map=${output}_filled color=elevation

Úkol
Dále stáhněte (stejné dlaždice) a naimportujte produkt DMP1G.
Výpočet model výšky porostu (CHM)¶
Canopy Height Model (CHM) je rozdíl výšek mezi digitálním modelem povrchu a terénu.
CHM vypočítejme pomocí nástroje mapové algrebry r.mapcalc:
Příklad CMH v tabulce barev differences:

Úkol
Stáhněte vrstvu budov z RÚIAN (např. pomocí QGIS pluginu). Tuto vrstvu s vhodně zvolenou obalovou zónou kolem budov použijte pro odstranění velkých rozdílů detekovaných CHM.
Tvorba modelu pro výpočet CHM¶
Výpočetní proces popsaný výše převedeme do formy modelu. Grafický
modelář spustíme  a postupně
přidáváme výpočetní nástroje
a postupně
přidáváme výpočetní nástroje  .
.
Výsledný model může vypadat následovně:
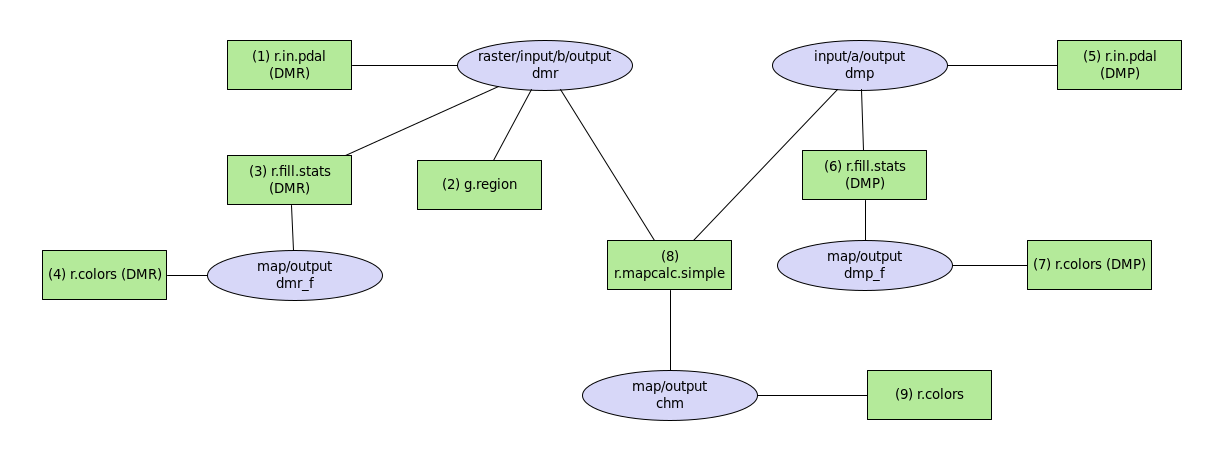
Model ke stažení zde.
Před spuštěním modelu vytvořme nový mapset.
Tip
Vytvořené vrstvy lze přidat automaticky do mapového okna z kontextovému menu nad datovou položkou (Display).
Parametrizace modelu¶
Uživatelské vstupy lze definovat dvěma způsoby:
- parametrizací jednotlivých parametrů použitých nástrojů v modelu
- použitím proměnných
Začněme parametrizací nástrojů. U každého parametru je možnost zvolit
"Parametrized in model". Pokud parametr vyplníme a přesto políčko
zašrtneme, parametr bude parametrizován s definovanou výchozí hodnotou.
Vyzkoušejme nastavit parametrizaci u r.in.pdal, a to u input a
resolution.
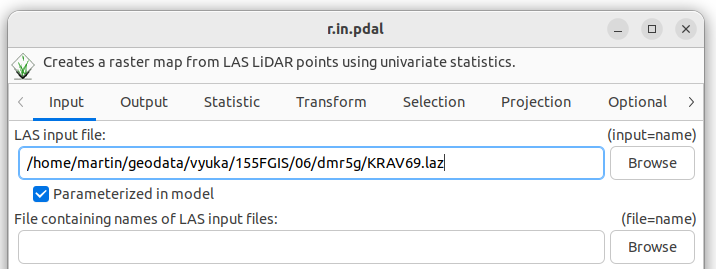
Po spuštění modelu se objeví dialog umožňující nastavení zvolených parametrů:
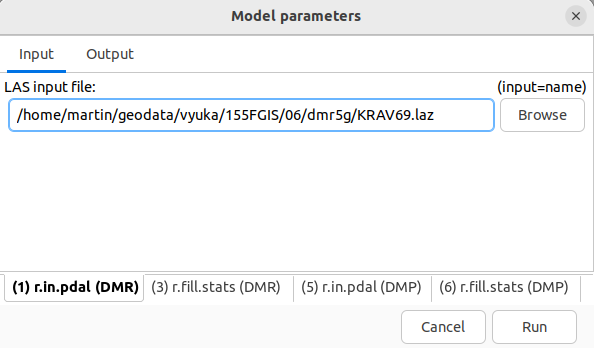
Podobně parametrizujme i ostatní uživatelské vstupy.
Upravený model ke stažení zde.
Tento způsob parametrizace modelu není ale v našem případě vhodný. Některé
parametry budou duplikovany, jako např. resolution v případě
r.in.pdal.
Upravme model s využitím proměnných. V založce Variables přidáme čtyři
proměnné:
pathCesta k adresáři se vstupními datytileOznačení dlaždiceresolutionCílové prostorové rozlišenífillPočet buněk pro výplnění děr
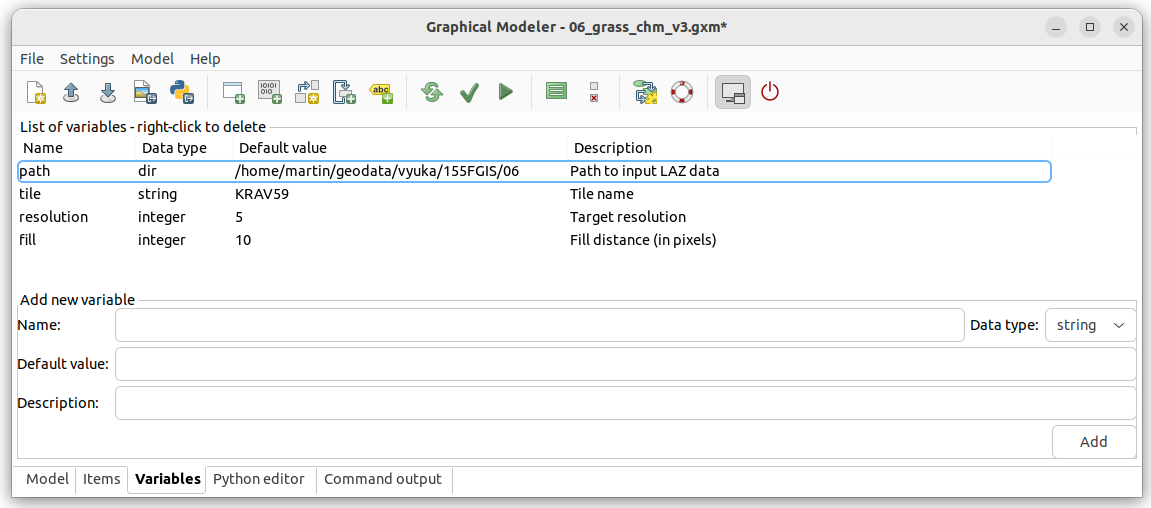
V parametrech se proměnné používají s prefixem %, v případě
parametru input nástroje r.in.pdal půjde o
%path/dmr5g/%tile.laz. Po spuštění modelu se opět objeví dialog pro
nastavení vstupních parametrů:
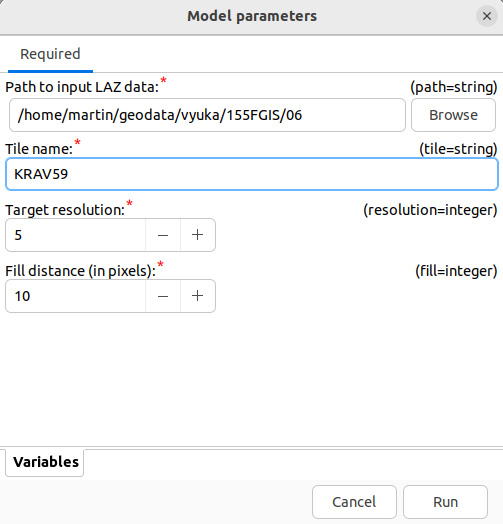
Upravený model ke stažení zde.
Úkol
Vyzkoušejte postupně zpracovat všechny stažené dlaždice.
Python API¶
GRASS nabízí hned několik Python balíčků, podrobnosti naleznete v dokumentaci. Zaměřme se na tři hlavní knihovny související s obsahem tohoto kurzu:
- GRASS Script Package jako vstupní brána do skriptovacích možností jazyka Python v GRASS GIS
- pyGRASS moderní objektově orientované Python API
- Temporal Framework Python API pro práci s časoprostorovými daty
PyGRASS je navržen jako objektově orientované API jazyka Python pro GRASS. To je zásadní rozdíl oproti GRASS Script Package, který se skládá z procedur - funkcí. Je důležité zdůraznit, že PyGRASS není náhradou za GRASS Script Package. Oba balíky existují vedle sebe. Záleží na uživateli, který balíček ve svých skriptech použije. V našem případě budeme používat pyGRASS.
Note
Aby toho nebylo málo, tak GRASS ve verzi 8.5 přichází s novým Python API pro spouštění výpočetních nástrojů - grass.tools.
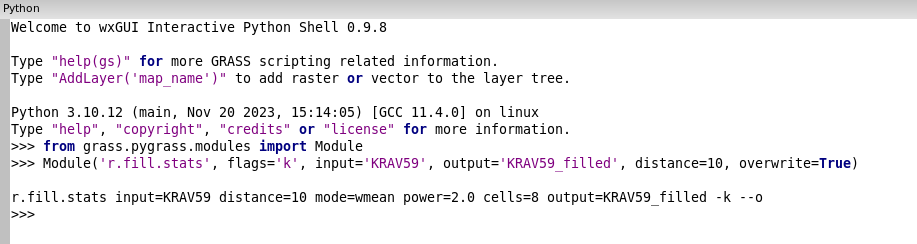
První kroky v jazyce Python provedeme v záložce Python. Syntax do
příkazové řádky, např.:
Lze jednoduše přepsat do syntaxe Python (zde v syntaxi PyGRASS):
from grass.pygrass.modules import Module
Module('r.fill.stats', flags='k', input='KRAV59', output='KRAV59_filled', distance=10, overwrite=True)
Vylepšení modelu ve formě Python skriptu¶
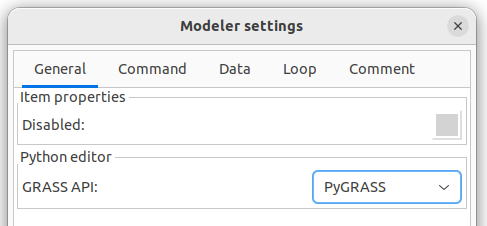
Model lze exportovat do formy skriptu v jazyku Python. Před exportem
ještě v nastavení modeláře  zvolíme PyGRASS API. Výchozím Python API je totiž GRASS Script
Package.
zvolíme PyGRASS API. Výchozím Python API je totiž GRASS Script
Package.
Poznámka
Volba nastavení Python API je dostupná od verze GRASS 8.4.
Po přepnutí do záložky Python editor se model převede do Python
syntaxe. Tu lze upravovat přímo v této záložce anebo uložit do souboru
na disk Save as.
Takto uložený skript lze upravovat ve vašem oblíbeném IDE. V našem
případě ale použijme jednoduchý vestavěný Python editor dostupný v
nástrojové liště  .
.
Vygenerovaný skript obsahuje bohužel chybu:
Úkol
Opravte chybu ve skriptu tak, aby šel spustit.
Úkol
Upravte skript, aby končil rozumně formulovanou chybou v případě, že vstupní soubor neexsituje.
Dále upravme skript tak, aby zpracoval všechny dostupné dlaždice najednou. Můžeme volit mezi dvěma možnostmi:
- využít parametr
filenástrojer.in.pdal - pomocí cyklu projít postupně vstupní LAZ soubory, každý zpracovat
odděleně a posléze vytvořit mozaiku pomocí
r.series(tato cesta by umožňovala zpracování dlaždic paralelizovat pomocíParallelModuleQueue- příklad najdete v GRASS Jena Workshop).
Zvolme první variantu. Skript upravíme následovně:
- odstraňme parametr skriptu
tile - vytvořme funkci
collect_files, která pro daný adresář vrátí seznam LAZ souborů. - seznam LAZ souborů předáme do parametru
filejako soubor uložený na disku anebo použijeme standardní vstup jako v ukázce níže. - odstraňme duplicitu kódu - vytvořme novou funkci
process_product()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 | |
Ukázka CHM (na pozadí ČÚZK WMS Ortofoto):

Přístup k datům¶
Pro přístup k rastrovým datům lze použít dvě třídy:
- RasterRow pro čtení a zápis po řádcích
- RasterSegment pro čtení a zápis po segmentech (dlaždicích)
Nejprve vypišme základní metadata:
from grass.pygrass.raster import RasterRow
with RasterRow('chm') as data:
print(data.info.cols, data.info.rows)
min, max = data.info.range
print(min, max)
print(max - min)
Dále zkusme reklasifikovat raster pomocí NumPy:
import numpy as np
from grass.pygrass.raster import RasterRow
with RasterRow('chm') as data:
array = np.array(data)
array[array < 2] = 1
array[(array > 2) & (array < 7) ] = 2
array[array > 7] = 3
print(np.unique(array, return_counts=True))
Podobně můžeme přístupovat i k vektorovým vrstvám pomocí Vector (bez topologie) a VectorTopo (včetně topologie).